There is a service called “IST Skola” which our daycare is using.
It’s an app for taking attendence, delivery and pickups and it is possible for the staff to share images and text from the preceeding days / weeks.
A couple of years ago they used another service called Truegroups. With that service it was possible to download the images and reports. We also got emailed copies of the images and reports.
When they changed to IST, it was not possible to download images, copy the reports or get an copy on email. The only “simple” way of making a copy of the images was by taking screenshots…
There are also some moral implications. There may be a reason why it’s not possible to download images, but all parents have signed consent allowing digital sharing images of their children. I am downloading the images because I want to save them for myself.
There are a lot of memories from the daycare and they are really just there, one has just to figure out a way to download those.
Finding out what goes on behind the scenes
To get a peek into the encrypted data sent between the phone and server, there is a tool called mitmproxy.
mitmproxy
General steps to get started:
- Download mitmproxy from https://mitmproxy.org/ or install with a package manager.
- Start the web interface (
mitmweb). - Install the root certificate on the device you’re capturing data for.
- Configure the device to use mitmproxy as a proxy on the WiFi SSID.
Open the app and navigate a few pages / screens.
If all goes well, there should be traffic on the mitmweb page.
GraphQL
After getting traffic in mitmweb, it reveals it uses GraphQl on the backend to request and fetch data.
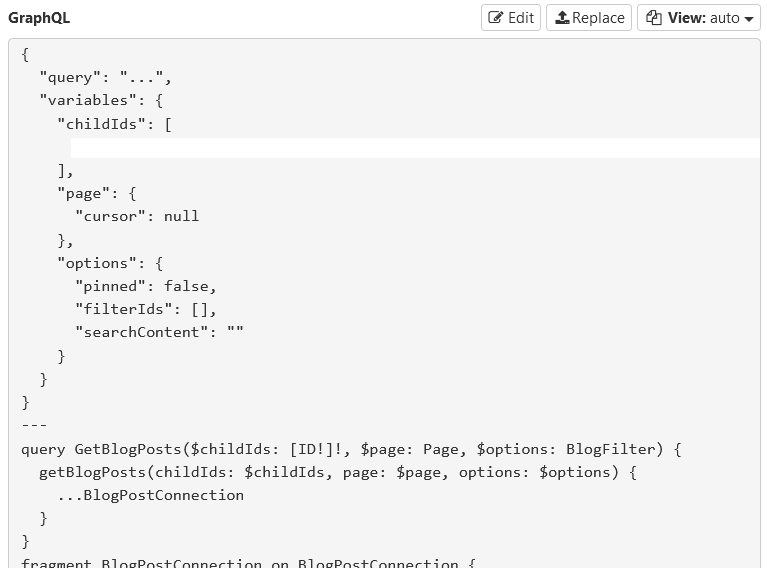
As a systems programmer, I have only heard about GraphQl, but not used it in any capacity.
But, as a systems programmer, I know HTTP is just a couple bits and bytes sent over the HTTP protocol. How difficult can it be to create a small client to download images?
GraphQL client
The main objective is to fetch all image attachments for all posts, and store them in one folder per post.
Python has a nice library called gql, which fits our purpose. So it was decided to write the client in Python.
After some experimenting with gql and the GraphQL API, it became apparent there were only 2 required pieces of data to fetch the resources, the Bearer Token and a Child ID. Both are available from the mitmproxy/web interface.
Userdata
Whenever there are more than 1 piece of data, I prefer to gather them in a class/struct.
# Userdata.py
class Userdata:
bearer_token: str = None
child_id: str = None
def __init__(self, bearer_token: str, child_id: str) -> None:
self.bearer_token = bearer_token
self.child_id = child_id
pass
def __repr__(self) -> str:
return f"Bearer: {self.bearer_token} Child: {self.child_id}"
Together it becomes:
bearer_token = "Bearer do.not.publish.this.token"
child_id = "some.base64.encoded.id"
userdata = Userdata(bearer_token, child_id)
Program flow
graph LR A(Create Userdata) --> B(Get posts) B --> C(For all posts) C --> D(Download and save post/images) D -->|Any remaining posts| C
See Also
- - Why do programmers need private offices with doors?
- - F22a Raptor Part Names
- - Languishing
- - Malapropism
- - ELI5 Physicists Say That Information Is Never Lost but How the Heck Is It Stored Then and What Theoretical Possibility Could Recover It